Archive for August 2019
基于关系记忆的知识图嵌入
翻译 机器海岸线
原文 Relational Memory-based Knowledge Graph Embedding
摘要
知识图嵌入模型经常受到记住现有三元组以预测新三元组的限制。 为了克服这个问题,我们引入了一种名为R-MeN的新型嵌入模型,该模型探索了一个关系存储网络来建模关系三元组。 在R-MeN中,我们简单地将每个三元组表示为3个输入向量的序列,其反复地与关系存储器交互。 该存储器网络被构造成使用存储器和输入向量上的自注意机制来引入新信息以返回用于进行时间步长的相应输出向量。 因此,我们获得3个输出向量,然后将元素成倍增加为单个向量; 最后,我们将此向量提供给线性神经层,以产生三元组的标量分数。 实验结果表明,我们提出的R-MeN在两个着名的基准标记数据集WN11和FB13上获得了三重分类任务的最新结果。
介绍
知识图表(KGs) – 以三元组(主体,关系,对象)的形式表示实体之间的关系,表示为(s,r,o) – 由于缺少许多知识图表,因此通常不足以进行知识呈现有效三元组(West et al。,2014)。因此,研究工作一直侧重于推断KG中遗漏的新三联体是否有效(Bordes等,2011,2013; Socher等,2013)。如(Nickel等人,2016; Nguyen,2017)所总结的,已经提出KG嵌入式模型来计算每个三元组的得分,使得有效三元组具有比无效三元组更高的分数。例如,三联(北京,中国城市)的得分高于(悉尼,中国城市)的得分。
传统的嵌入模型,如TransE(Bordes等,2013),TransH(Wang等,
2014),TransR(Lin et al。,2015),TransD(Ji et al。,
2015),DISTMUET(Yang等人,2015)和Com plEx(Trouillon等人,2016),经常使用简单的线性算子,例如加法,减法和乘法。此外,一些基于深度卷积神经网络(CNN)的模型如ConvE(Dettmers等,2018)和ConvKB(Nguyen等,2018b)已成功应用于三元组评分。然而,这些方法仍然没有提供一种有效的方法来编码来自现有有效三元组的潜在知识来预测新知识。
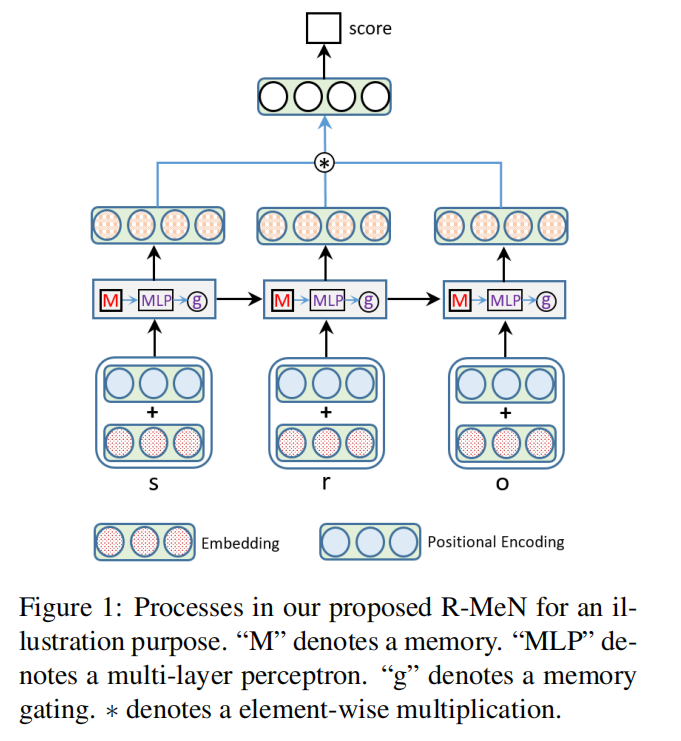
在本文中,我们利用关系记忆网络(Santoro et al。,2018)来提出R-MeN来预测KG中遗漏的新三元组的真实事实。我们的动机来自这样一个事实,即关系记忆网络已被证明比长期短期记忆网络(LSTMs)(Hochreiter和Schmidhuber,1997)在NLP任务(如语言建模)中更强大(Santoro et al。,2018) )和文本生成(Weili Nie和Patel,2019)。直观地,记忆交互以及在每个时间步的存储和检索可以帮助更好地从现有三元组中获取新信息,以解决先前KG嵌入模型的问题。特别地,每个三元组被转换成3个向量的序列,这些向量是我们的R-MeN的输入。在每个时间步长,使用自我关注机制(Vaswani等人,2017)将一个矢量输入与存储器相比较以合并新信息并产生输出矢量。将三个输出矢量逐元素地乘以单个矢量,然后使用该矢量通过加权线性层返回输入三元组的分数。
总之,本文的主要贡献如下:
•我们提出了一种嵌入模型R-MeN,它使用关系存储网络来建模关系三元组。据我们所知,我们的工作是探索知识图的关系记忆网络的首要考虑因素。
•我们在两个着名的基准数据集WN11和FB13上评估我们的R-MeN三重分类任务(Socher等,2013)。实验结果表明,R-MeN比先前最先进的嵌入式模型获得更好的性能。特别是,R-MeN在WN11和WN11上产生了新的最高精度

4。结论
我们提出了R-MeN-一种新的嵌入模型,它使用关系存储网络来模拟知识图中的关系三元组。 实验结果表明,我们的R-MeN在WN11上实现了新的最高精度,在FB13上实现了三重分类任务的第二高精度。 在未来的工作中,我们计划扩展我们的R-MeN,以使用关系路径和外部协议来进行多跳知识图推理。 我们的代码位于:https:// anonymous-url /。
高效的知识图谱准确性评估
翻译 机器海岸线
原文 Efficient Knowledge Graph Accuracy Evaluation
摘要
估计大规模知识图(KG)的准确性通常需要人们从图中注释样本。如何在保持人类注释成本低的同时获得具有统计意义的精度评估估计是对KG及其实际应用的开发周期至关重要的问题。值得一提的是,这个具有挑战性的问题在以前的研究中基本上被忽略了。为了解决这个问题,本文提出了一个有效的抽样和评估框架,旨在提供具有强大统计保证的质量准确性评估,同时最大限度地减少人力。在实践中观察到的注释成本函数的属性的推动下,我们建议使用聚类采样来降低总体成本。我们进一步应用加权和两阶段抽样以及分层以获得更好的抽样设计。我们还扩展了我们的框架,以便对不断发展的KG进行有效的增量心理评估,引入两种基于分层抽样和水库抽样加权变量的解决方案。对现实世界数据集的广泛实验证明了我们提出的解决方案的有效性和有效性。与基线方法相比,我们的最佳解决方案可以在静态KG评估中降低高达60%的成本,并在不降低评估质量的情况下,在不断发展的KG评估中降低高达80%的成本。
一,简介
在过去几年中,我们已经看到越来越多的大规模幼稚园以RDF三元组(主题,谓语,客体)的形式拥有数百万关系事实。例子包括DBPe-dia [1],YAGO [15,5],NELL [25],Knowledge-Vault [13]等。然而,KG的构建过程远非完美,因此这些KG可能包含许多不正确的事实。了解KG的准确性对于改进其构建过程(例如,更好地了解摄取的数据质量和各种处理步骤中的缺陷)以及告知下游应用程序并帮助他们应对数据质量的任何不确定性至关重要。尽管其重要性,但是先前的学术研究在很大程度上忽略了有效且可靠地评估KG精度的问题。
KG精度可以定义为KG中三元组的百分比是正确的。在这里,如果对应关系与现实生活中的事实一致,我们认为三元组是正确的。从典型上讲,我们依靠人类对三元组正确性的判断。现代幼稚园规模的人工评估令人望而却步。因此,最常见的做法是在(相对较小的)KG样本上进行人工注释,并根据样本计算KG精度的估计值。一种天真且流行的方法是从KG手动将三元组随机抽样。一个小样本集转换为降低手动注释成本,但它可能会偏离真正的精确度。为了获得具有统计意义的估计,必须对大量“足够”的三元组进行采样,因此增加了注释的成本。另一个实际的挑战是KG随着时间的推移逐渐发展,因为新的事实被提取并添加到KG中,其准确性也相应地发生变化。假设我们已经评估了KG的先前版本,我们希望逐步评估新KG的准确性,而无需从头开始。
为了激励我们的解决方案,让我们详细研究一下手动注释过程的工作原理。我们使用表1中所示的两个注释任务作为示例。

例1.1。对现实生活实体的提及可能含糊不清。例如,Taskl的第一个三重奏,名称“迈克尔乔丹,可以指不同的人 – 迈克尔乔丹的名人堂篮球球员或迈克尔乔丹杰出的计算机科学家?前者出生在纽约,而后者出生在洛杉矶。在我们验证主体和客体之间的关系之前,首要任务是确定每个实体.1如果我们评估一个我们已经确定的实体的新三元组,总评估成本将是与从看不见的实体评估一个新的三元组相比较低。例如,在任务2中,所有三元组都与迈克尔乔丹的实体相同。一旦我们将这个迈克尔乔丹识别为篮球运动员,注释者可以轻松评估这些三元组的正确性而无需进一步识别相反,在Taskl中,五个不同的三元组大约有五个不同的实体。每个三元组的注释过程是独立的,注释器需要花费额外的努力才能确定。为他们每个人设置可能含糊不清的实体,即电视连续剧的朋友或电影的朋友? 2008年的电影“暮光之城”还是1998年的Twi电影?显然,给定注释的三元组数量相同,Task2花费的时间更少。此外,验证关于同一实体的三元组也是一项更容易的任务。 〔在实际的注释任务中,每个三元组都与一些上下文信息相关联。注释者需要花时间首先识别主题,对象或两者。例如,关于演员/女演员的WiKi页面包含该人的大部分信息或关于电影的IMDb页面列出其综合特征。注释器可以在单个(或有限数量)源中同时验证关于同一实体的一组三元组,而不是仅仅为了验证单个事实而在多个源之间进行搜索和导航。
因此,一般而言,关于同一实体(作为Task2)的三元组审计可以比不同实体(作为Task1)的三元组成本更低。不幸的是,考虑到KG规模的百万甚至十亿规模,选择单个三元组更有可能产生作为Taskl的评估任务。
如上例所示,在为大型KG设计采样方案时,采样三元组的数量不再是注释成本的良好指标 – 相反,我们应该注意手动注释成本函数的实际属性。在我们的抽样设计中。我们的贡献是四方面的:
•我们提供迭代评估框架,保证提供高质量的准确性评估和强大的统计一致性。用户可以指定估计结果的误差限制,并且我们的框架会迭代地进行采样和估计。一旦估计误差低于用户要求的阈值,它就会停止,而不进行过采样和不必要的手动评估。
•利用注释成本的属性,我们建议应用具有不等概率理论的集群抽样,从而实现有效的人工评估。我们通过将其与近似评估成本相关联来定量地推导出KG中的最佳采样单元尺寸。
•可以扩展拟议的评估框架和抽样技术,以便对不断发展的幼稚园进行增量评估。我们分别介绍了基于分层抽样和储层抽样加权变量的两种有效的增量评估解决方案。它们都使我们能够重复使用先前评估过程的评估结果,从而显着提高评估效率。
•对各种现实生活中的KG进行了广泛的实验,包括地面实况标签和合成标签,证明了我们的解决方案相对于现有基线的效率。对于静态KG的评估任务,我们的最佳解决方案可将营业成本降低60%。对于不断发展的KG的评估任务,基于分层抽样的增量评估可将成本降低高达80%。
据我们所知,这项工作是率先提出一个实用的评估框架,为静态和不断发展的KG提供高效,无偏见,高质量的KG准确度评估。虽然我们主要关注知识图的准确性评估,但我们提出的评估框架和抽样技术是一般性的,可以扩展到关系数据库(具有适当的实体和关系概念)。
本文的其余部分安排如下。第2节重新审视了KG准确度评估的关键概念,并正式定义了问题。第3节提出了一个评估模型,并分析了人类注释器在不同的评估任务中的表现,这些评估任务激发了我们的解第4节介绍了我们的总体评估框架。第5节和第6节介绍了一套全面的采样技术,可以对静态KG和不断发展的KG进行有效的质量评估。第7节对我们的解决方案进行实验评估。最后,我们回顾了第8节中关于KG准确度评估的相关工作,并在第9节中进行了总结。
8.相关工作
如前所述,SRS是一种简单但普遍的KG精度评估方法。超越SRS,Ojha等。 [26]是第一个系统地解决大规模幼稚园高效准确性评估问题的人。一个关键的观察是,通过在KG的三元组中探索依赖关系(即类型一致性,Horn-子句耦合约束[7,25,21]和正/负规则[27]),可以传播正确性评估三元组与其他未评估的三元组。他们解决方案的主要思想是选择一组三元组,以便了解这些三元组的正确性可以推断出KG最大部分的正确性。然后,使用所有标记的三元组估计KG精确度。他们基于概率软逻辑的推理机制[8]可以显着节省手动评估三元组正确性的努力。但是,将他们的方法应用于我们的设置存在一些问题。首先,推理过程是概率性的,并且可能导致错误的真/假标签的支持。因此,很难将该过程引入的偏差评估为准确度估计。第二,KGEval依赖于昂贵[根据[26],需要超过5分钟才能找到手动评估的下一个三重奏,即使在小于2,000三倍的小型KG上也是如此。](机器时间)推理机器anism,在大型幼稚园没有很好的规模。最后,他们没有解决不断发展的幼稚园的准确性评估。我们总结了表8中这些现有方法之间的比较。
幼稚园的准确性评估也与幼稚园或“关联数据”的错误检测和事实验证密切相关[19]。相关工作包括数字错误检测[22],通过众包进行错误检测[6],多重匹配KGs [23],通过网络搜索[17]等进行事实验证。但是,上面提到的上述工作都有其自身的局限性,到目前为止尚未被用于有效的KG准确性评估。

另一系列相关工作在于数据清理[11],其中使用基于抽样的统计理论基础的方法来提高效率。在[24]中,作者设计了一种新颖的连续采样器和相应的估计器,以便对实体解析的任务提供有效的评估(F测量,精确度和召回)[10]。采样框架从有偏见的仪器分布中依次绘制样本(并要求标记),并在收集更多样本时即时更新分布,以便快速关注提供更多信息的未标记项目。王等人。 [29]考虑将基于采样的近似查询处理[20]与数据清理相结合,并提出了一个样本 – 清理框架,以便对脏数据进行快速聚合查询。他们的解决方案充分利用了两个方面,并提供准确的查询答案,并且查询时间快。然而,上面提到的工作没有利用我们设置中实践中出现的注释成本函数的特性 – 他们专注于减少人工标记或清理的记录数量,但忽略了机会使用聚类来提高效率。
9.CONCLUSION
在本文中,我们已经开始全面研究高效可靠的知识图谱评估的重要问题。 我们提出了一个适用于静态和不断发展的KG的通用评估框架。 我们设计了一套采样技术,用于对这两种情况进行有效的准确性评估。 通过对具有三重正确性的真实和合成标签的各种KG的实验证明,与现有基线方法相比,我们的解决方案可以显着加快准确度评估过程。 未来的工作包括扩展建议的解决方案,以便能够对不同的粒度进行有效评估,例如每个谓词或每个实体类型的准确性。
图像质量评估和色差
翻译 机器海岸线
原文 Image Quality Assessment and Color Difference
摘要 – 一个普通的健康人并不仅仅是黑白分明的世界。此外,感知世界不是由像素组成,而是通过视觉人类感知结构。然而,采集和显示系统使世界离散化。因此,我们需要考虑像素,结构和颜色来模拟体验质量。质量评估方法使用像素和结构指标,而颜色科学方法使用基于补丁的颜色差异。在这项工作中,我们通过扩展CIEDE2000公式和感知色差来组合这些方法,以评估图像质量。我们研究了与LIVE数据库上的PSNR,CIEDE2000,SSIM,MS-SSIM和CW-SSIM相比,基于感知色差的度量(PCDM)的执行情况。在线性相关方面,PCDM在白噪声(97.9%),Jpeg(95.9%)和Jp2k(95.6%)下获得了相容的结果,总相关性为92.7%。我们还展示了PCDM捕获基于结构的指标无法捕获的基于颜色的工件。
索引术语 – 色差,感知质量,客观质量指标,颜色伪影
一,导言
图像处理文献中的短语“体验质量”表示图像的感知质量。因此,感知与消费电子应用的保真度同样重要。通常根据图像处理文献中的像素和结构来分析图像。然而,色彩科学文献主要关注视觉领域功能的大片。在我们看来,为了模拟全面的体验质量,我们需要考虑图像处理和色彩科学的文献。所提出的方法通过利用经验评估质量中的颜色标签差异来贡献文献。
客观质量指标用于图像处理文献中,以估计经验质量或量化扭曲。像素保真度指标集中于图像像素之间的精确差异。例如,均方根误差和峰值信噪比(PSNR)由于其简单性而在文献中常用。代替计算像素保真度,图像的结构保真度也用于估计质量。 SSIM在单一尺度上计算图像的局部统计量,而MS-SSIM遵循多尺度方法,使用如[1]中所述的拉普拉斯金字塔来计算不同分辨率下的SSIM。 CW-SSIM [2]也遵循多尺度方法,但不使用计算空间域中的局部统计量,而是使用小波系数。大多数这些质量指标使用亮度分量或灰度图像而忽略了颜色通道。

与基于亮度的图像质量测量相比,颜色信息通常用于颜色科学文献中以检测相似色调之间的差异[3]。国际照明委员会(CIE)负责照明相关技术标准(包括色差)的国际协调。 CIEDE2000色差方程由CIE技术委员会开发,它是[4],[5]中描述的色彩科学文献中的最先进的度量标准之一。颜色差异和相似性可以用作图像的描述符。 [6]中的作者提出了从真实世界图像中学习颜色名称,可以用于物体识别和图像分类,如[7]中所述。如[8]中所解释的,在图像的美学质量方面,颜色命名描述符也用于图像分类。此外,在[9]中使用颜色命名描述符来执行基于颜色的边缘检测。
色差公式通常用于色调匹配以用于色彩再现。 [10]中的作者使用基于色差的度量来预测打印机半色调图案的纹理可见性。在[10]中使用色差的方式可以被认为是色差方程的应用领域中从基本色调匹配到纹理图像比较的过渡。在[11]中,作者讨论了图像质量,差异和外观之间的联系。在这些方法中甚至讨论了彩色图像质量,作者从色彩科学的角度考虑问题,并且在没有充分研究客观质量度量及其在压缩和通信错误等不同类型的失真下的性能的情况下使讨论受限。 [12]中的作者将差分方程更进一步,并描述了实验条件下色差方程的校准过程以及CIEDE2000作为图像质量度量的用法。然而,忽略了差分方程的一个非常基本的特征。原则上,CIEDE2000设计用于相似颜色之间的色调匹配,这些颜色受到最多中等差异的限制,并且不用于显着的色调差异。

在本文中,我们用[9]中的感知色差来扩充CIEDE2000公式的范围,以概括作者在[12]中提出的方法。在第II节中,我们描述了建议的质量度量管道中的主要块。我们在第III节讨论实验装置,结果和观察结果,并在第IV节中结束我们的讨论。
IV。 结论
在本文中,我们使用估计图像的主观质量来扩展CIEDE2000公式。 我们已经证明,感知色差度量结果与DMOS高度相关,并且在相关性和均方根误差方面表现优于像素方式保真度度量和CIEDE2000公式。 但是,由于PCDM中的过采样,结构度量在快速衰落和高斯模糊下的性能优于基于颜色的度量。 当采样率增加时,PCDM表现更好,但也会显着增加时间复杂度。 我们开始结合基于颜色和结构的指标来估计最终用户的体验质量,并且混合指标已经在LIVE和TID2013图像数据库中产生了有希望的结果。
学会描述相似图像对之间的差异
翻译 机器海岸线
原文 Learning to Describe Differences Between Pairs of Similar Images
摘要
在本文中,我们介绍了自动生成文本的任务,以描述两个相似图像之间的差异。 我们根据从视频监控镜头中提取的成对图像帧的众包差异描述来收集新的数据集。 要求通知人简明扼要地描述短段中的所有差异。 结果,我们的新颖数据集提供了一个探索模式,使语言和视觉保持一致,并捕捉视觉显着性的机会。 数据集也可以是连贯多句子生成的有用基准。 我们执行第一遍视觉分析,将不同像素的聚类暴露为对象级差异的代理。 我们提出了一种模型,通过使用潜变量来对齐不同像素的簇与输出传感器,从而捕获视觉显着性。 我们发现,对于单句生成和多句生成,所提出的模型优于仅使用注意力的模型。
介绍
人类用户与数据集合之间的接口是人工智能(Al)技术的重要应用领域。我们能否构建能够有效解释数据并以自然语言简洁地呈现其结果的系统?人工智能最近的一个目标是建立能够互相预测和描述视觉数据的模型,以帮助人类完成各种任务。例如,图像字幕系统(Vinyals等人,2015b; Xu等人,2015; Rennie等人,2017; Zhang等人,2017)和vi sual问答系统(Antol等人,2015; Lu等人,2016; Xu和Saenko,2016)可以帮助视障人士与世界互动。机器可以帮助人类的另一种方式是识别数据中有意义的模式,选择和组合显着的模式,并生成简洁和流畅的“人类消费品描述。例如,文本总和化(Mani和Maybury,1999; Gupta)和Lehal,2010; Rush等,2015)在自然语言处理中一直是一个长期存在的问题,旨在提供一系列文档的简明文本摘要。
在本文中,我们提出了一个新的任务和包含图像标题和摘要元素的数据集:“spot-the-diff5”的目标是生成一对简单的SIM卡之间的所有显着差异的简洁文本描述ilar图像。除了是一个有趣的谜题之外,这个任务的执行可能会有应用程序作为sisted监视,以及计算机辅助跟踪媒体资产的变化。我们收集并发布一个新任务的数据集,对于自然语言和计算机视觉研究社区都有用。我们使用众包来收集视频监控录像中成对图像帧之间差异的文本描述(Oh et al。,2011),要求注释者简洁地描述所有显着的差异。总的来说,我们的数据集包括13,192个图像对的描述。图I显示了一个示例数据点 – 一对图像以及两个图像之间差异的文本描述。
有许多有趣的建模挑战与生成图像之间差异的自然语言摘要的任务相关联。首先,并非所有低级视觉差异都足以保证描述。该数据集为尝试学习视觉显着性模型的方法提供了一个有趣的超视觉来源(我们还使用基线显着性模型进行探索性实验,如后所述)。其次,在描述视觉差异时,人类使用不同的抽象层次。例如,当多个附近的对象全部协调地移动成对的图像时,注释器可以将该组称为单个概念(例如“汽车行”)。第三,给定一组显着差异,规划描述顺序并生成多个句子的流畅序列本身就是一个具有挑战性的问题。所提出的任务的这些方面共同使其成为几个研究方向的有用基准。
最后,我们尝试基于神经图像捕获的方法。由于显着性差异通常在对象级而不是在像素级进行描述,因此我们将这些系统置于首次通过视觉分析上,该分析将不同像素的聚类暴露为对象级差异的代理。我们提出了一个使用潜在的discrete变量的模型,以便将差异簇与输出句子直接对齐。此外,我们在企业中学习了先前学习这些差异集群的视觉显着性。我们观察到所提出的使用对齐作为离散潜在变量的模型优于仅使用注意力的那些模型。

5讨论与分析
输出的定性分析我们对输出进行定性分析,以了解当前方法的缺点。当前方法的一个明显局限是未能明确地模拟两个图像中相同对象的移动(图7) – 对象跟踪的先前工作在这里是有用的。有时模型会使对象的某些属性错误,例如“蓝色汽车”代替“红色汽车”。一些输出预测表明一个对象有“出现5而不是”消失5,反之亦然。
模型是否学习句子和差异群集之间的对齐?我们通过让两个人手动注释句子和差异簇之间的黄金对齐,对50个图像对进行了研究。然后,我们计算了modeFs预测对齐的对齐精度。为了获得给定句子的模型预测对齐,我们计算argmaxkP(Zi = k \ X)P {Si \ zi = k)X)。我们提出的模型精度达到54.6%,比随机机率提高了27.4%。
用于预处理的聚类我们的生成算法假定一个句子只使用一个聚类,因此我们调整聚类方法的超参数以获得大聚类,这样通常聚类将完全包含报告的差异。在检查随机选择的数据点时,我们观察到在某些情况下,太大的簇被聚类过程标记。缓解这种情况的一种方法是调整聚类参数以获得更小的聚类,并更新生成部分以使用聚类的子集。如前所述,我们将聚类视为实现对象级预处理的手段。一个可能的未来方向是利用预先训练的物体检测模型来检测汽车,卡车,人员等,并使这些预测容易地用于生成模型。
多句子训练和解码如前所述,我们在模型中查询所需数量的句子\在未来的作品中,我们希望放松这个假设并设计能够预测句子数量的模型。另外,我们提出的模型并没有明确地确保给定数据点的不同句子的潜在变量的一致性,即该模型没有明确地使用句子报告非重叠视觉差异的事实。在保持培训可行性的同时实施这些知识是未来潜在的工作方向。

6相关工作
对语用学进行建模:数据集提供了一种测试方法的机会,这些方法可以对语义学和语义,空间和视觉相似性进行建模,并生成对从一个图像到另一个图像的变化的文本描述。在此方向上的一些先前工作(Andreas和Klein,2016; Vedantam等,2017)对比地描述了存在牵引器的目标场景。在另一个相关的任务 – 参考表达理解(Kazemzadeh等人,2014; Mao等人,2016; Hu等人,2017) – 模型必须识别图像中的哪个对象被给定的句子引用。但是,我们提出的任务带来了与摘要相关的实用目标:目标是识别和描述所有差异。由于目标定义明确,因此可以用来约束试图了解人类如何描述视觉差异的模型。
自然语言生成:自然语言生成(NLG)具有以前工作的丰富历史,包括例如最近关于传记生成的工作(Lebret等,2016),天气报告生成(Mei等人,2016)和食谱一代(Kiddon等,2016)。我们的任务是多句文本生成,因为它涉及组合多个句子以简洁地涵盖一组差异。
视觉基础:我们的数据集还可以为训练无人监督和半监督模型提供有用的基准,这些模型可以学习视觉和语言。 Plummer等。 (2015)收集了图像字幕数据集中短语区域对齐的注释,并且已经尝试跟进工作来预测这些对齐(Wang等人,2016; Plummer等人,2017; Rohrbach等人,2016)。我们提出的数据集提出了一个相关的对齐问题:尝试将句子或短语与视觉差异对齐。然而,由于差异是上下文并且依赖于视觉比较,因此随着建模技术的进步,我们的新任务可能代表更具挑战性的场景。
图像变化检测:有一些关于土地利用模式变化检测的工作((Radke等,2005))。这些作品是相关的,因为它们试图筛选出噪声并在不同时间标记处标记相同区域的两个图像之间的变化区域。 Bruzzone和Prieto(2000)提出了一种无监督的变化检测算法,旨在区分多时相遥感图像的变化和未变化的像素。 Zanetti和Bruzzone(2016)提出了一种方法,允许未更改的类更复杂,而不是只有一个未更改的类。虽然图像差异检测是我们管道的一部分,但我们的最终任务是生成自然语言描述符。此外,我们观察到简单的聚类似乎对我们的数据集很有效。
其他相关工作:Maji(2012)旨在通过模拟注释任务来构建零件和属性的词典,其中要求注释者描述两个图像之间的差异。一些其他相关的作品模型短语描述颜色的变化(Winn和Muresan,2018),移动游戏评论描述游戏状态的变化(Jhamtani等,2018),以及代码提交消息总结(Jiang et al。,2017)。存在一些关于细粒度图像分类和字幕2a的先前工作
2006; Khosla等,2011)。这类工作的前提是机器难以在类似物体之间找到明显的本机特征,例如:不同种类的鸟类。这些作品对我们来说很重要,因为我们处理的数据类型通常是a
条件。
7结论
在本文中,我们提出了描述相似图像对之间差异的新任务,并引入了相应的数据集。与许多以前的图像字幕数据集相比,“Spot-the-difF”数据集中的文本描述通常是多句子的,包括大多数情况下两个相似图像中的所有差异。我们对数据集进行了探索性分析,并强调了潜在的研究挑战。我们将讨论我们的’Spot-the-difF数据集如何用于语言视觉对齐,引用表达式理解和多句子生成等任务。我们对图像执行了像素和对象级别预处理,以识别不同像素的聚类。我们观察到,所提出的将不同像素的群集与输出句子对齐的模型比仅使用注意力的模型表现得更好。我们还讨论了当前方法的一些局限性和未来方向的范围。
用于序列标记的嵌入状态潜在条件随机场
翻译 机器海岸线
原文 Embedded-State Latent Conditional Random Fields for Sequence Labeling
摘要
复杂的文本信息提取任务通常被赋予序列标记或低分析,其中使用通过在具有约束转换的图形模型中通过概率推理进行一致的局部标签来提取字段。最近,通过使用由重复神经网络(例如LSTM)提取的丰富特征对这些模型进行局部参数化是很常见的,同时通过简单的线性链模型强制执行一致的输出,表示连续之间的Marko vian依赖性标签。然而,简单的图形模型结构掩盖了输出标签之间经常复杂的非局部约束。例如,许多字段(例如名字)只能固定固定次数,或者在其他字段中存在。虽然RNN为序列标记提供了越来越强大的上下文感知功能,但它们尚未与输出分配中具有相似表现力的全局图形模型集成。我们的模型超越了lin耳链CRF,为每个输出标签合并了多个隐藏状态,但是使用低等级对数潜在评分矩阵对其过渡进行了简单的参数化,有效地学习了隐藏状态的嵌入空间。这种增强的推理变量潜在空间补充了RNN的丰富特征表示,并允许精确的全局推断服从复杂的,学习的非局部输出约束。我们试验了几个数据集,并表明当推理调整需要全局输出约束时,模型优于基线CRF + RNN模型,并探索可解释的潜在结构。
介绍
与涉及复杂结构化输出的许多其他预测任务一样,例如图像分割(Chen et al。,2018),机器翻译(Bahdanau et al。,2015)和语音识别(Hinton等, 2012),用于序列标记和浅层分析的深度神经网络(DNN)已成为信息提取的标准工具(Collobert等,2011; Lample等,2016)。在结构化预测的语言中,DNN处理输入序列以产生用于输出预测模型的丰富的局部参数化。但是,输出变量遵循各种硬约束和软约束 – 例如,在序列标记任务(如命名实体识别)中,I-PER不能遵循B-ORG。

有趣的是,即使有如此强大的本地功能,DNN模型也不会仅通过本地决策自动捕获输出分布模式,并且可能违反这些限制。成功应用DNN来限制标记从合并简单线性链概率图形模型获得一致的输出预测(Collobert等,2011; Lample等,2016),以及更多的增加强制输出标签一致性的图形模型是其他任务(如图像分割)的常见做法(Chen et al。,2018)。
以前在DNN特征序列标签中的工作以及用于信息提取的图形模型将其输出结构建模限制为这些简单的本地马尔可夫依赖性。在这项工作中,我们探索了潜在变量的增加到预测模型,并通过一个分析的分解参数结构,在图形模型中执行隐藏状态嵌入的表示学习,补充表示学习的标准实践在分割模型的局部潜力。通过对隐藏状态转移矩阵的对数势进行因式分解,我们能够学习大量隐藏状态而不会过度拟合,而潜在动力学则增加了学习全局预测的全局约束的能力,而不会产生高效的精确度。推理。
虽然软和全局约束在序列标记方面具有丰富的历史(Koo等人,2010; Rush和Collins,2012; Anzaroot等人,2014),但在基于神经网络的特征提取模型的背景下,它们未得到充分研究。 。作为回应,我们提出了一种潜变CRF模型,该模型具有一种新颖的机制,用于学习la tent帐篷约束而不会过度拟合,使用低基数嵌入的大基数潜在变量。例如,这些非局部约束出现在细粒度嵌套字段提取中,这需要实体的子标签之间的层次一致性。此外,信息提取和插槽填充任务通常需要特定于域的约束 – 例如,我们必须避免多次提取相同的字段。需要一个良好的输入特征和输出建模组合来捕获这些结构依赖性。
在大量潜在状态之间轻微参数化的过渡函数。我们引入一个隐藏状态变量,并在隐藏状态空间而不是标签状态空间中学习模型动态。这放宽了输出标签之间的马尔可夫假设,并允许模型学习全局约束。为了避免在具有潜在状态空间大小的参数中的二次爆炸,我们将过渡对数势分解为低秩矩阵,通过有效地学习潜在状态的简约表示来避免过度拟合。虽然低秩Zog-势矩阵不能证明测试时推理速度,但我们可以执行精确的Viterbi推理来计算标签序列。图1显示了一个示例,其中我们的模型通过遵守从训练数据中学习的全局约束,在标准DNN + CRF模型失败时找到正确的标记序列。
我们在两个数据集上检查嵌入状态潜在CRF的性能:引用UMass Citations数据集上的引文和CLEF数据集上的医学记录字段提取。我们观察到两个任务的性能都有所提高,其输出服从于RNN功能无法捕获的复杂结构依赖性。我们最大的改进来自医疗领域,小型培训套件为我们的简约方法提供输出代表学习的额外优势。
6结论和未来的工作
我们提出了一个潜变量模型,它不仅利用来自深度神经网络的学习特征来参数化局部势,而且在大的隐藏状态空间中学习嵌入式表示,利用输入和输出表示中的特征学习。实验结果表明,我们的模型可以在存在模糊信息的情况下学习全局结构依赖性,这些模糊信息无法通过输入序列的局部特征来解决。我们在输出状态嵌入中找到可解释的结构。
未来的工作将把我们的模型应用于具有更复杂依赖性的更大数据集,并且在每个时间步骤中引入多个潜在状态,以精确推断为代价在输出状态中指数地表达更多的表达性。我们还将探索近似推理方法,例如期望传播,以加速低秩对数势系统中的消息传递。
一种用于多标签文本分类的深度强化序列到集合模型
翻译 机器海岸线
原文 A Deep Reinforced Sequence-to-Set Model for Multi-Label Text Classification
摘要
多标签文本分类(MUTC)旨在为数据集中的每个样本分配多个标签。标签通常具有内部相关性。然而,传统的方法倾向于忽略标签之间的相关性。为了捕获标签之间的相关性,序列到序列(Seq2Seq)模型将MUTC任务视为序列生成问题,这在该任务上实现了优异的性能。但是,Seq2Seq模型本质上不适合MUTC任务。原因是它需要人类预定义输出标签的顺序,而MUTC任务中的一些输出标签基本上是无序集合而不是有序序列。这与Seq2Seq模型对标签订单的严格要求相冲突。在本文中,我们提出了一种利用深度强化学习的新型序列到集合框架,它不仅捕获了标签之间的相关性,而且还减少了对标签顺序的依赖性。广泛的实验结果表明,我们提出的方法大大超过了竞争基线。
介绍
多标签文本分类(MLTC)是自然语言处理(NLP)中的一项重要但具有挑战性的任务,其目的是为数据集中的每个样本分配多个标签。它可以应用于许多真实场景,例如文本分类(Schapire和Singer 2000),标签推荐(Katakis,Tsoumakas和Vlahavas 2008),形成检索(Gopal和Yang 2010)等等。 。
探索MLTC任务的早期工作侧重于传统的机器学习算法。例如,二元相关(BR)(Boutell等人,2004)将MLTC任务分解为独立的二元分类问题。但是,它忽略了标签之间的相关性。大部分工作,包括ML-DT(Clare和King 2001),Rank-SVM(Elisseeff和Weston 2002),LP(Tsoumakas和Katakis 2006),ML-KNN(Zhang和Zhou 2007)和CC(Read et al.2011),努力模拟标签之间的相关性。然而,当考虑高阶标签相关性时,它们在计算上是难以处理的。
最近的研究转向深度神经网络,这在NLP领域取得了巨大成功。尽管它们表现出一定程度的改进,但大多数神经网络模型(Zhang和Zhou 2006; Nam等人2013; Benites和Sapozhnikova 2015; Baker和Korhonen 2017)都没有很好地捕捉标签之间的高阶相关性。杨等人。 (2018)提出应用具有注意机制的Seq2Seq模型来解决MLTC任务,其实现了优异的性能。通过递归神经网络(RNN)的强大能力来模拟序列依赖性,很好地捕获了标签之间的高阶关系。
但是,Seq2Seq模型本质上不适合MLTC任务。 Seq2Seq模型使用最大似然估计(MLE)方法和交叉熵损失函数进行训练,该函数依赖于严格的标签顺序。之前的工作(Vinyals,Bengio和Kudlur 2015)证明了订单对Seq2Seq模型的性能有很大影响,这也在我们的实验中得到验证。因此,需要仔细预定输出标签的顺序。仅当存在完美的标签顺序时才将Seq2Seq模型应用于MLTC任务是合理的。完美的标签订单意味着输出标签中有严格的顺序,这种真正的标签顺序在实践中是已知的。但是,由于以下原因,通常无法使用完美的标签订单:
•某些标签自然无序。对这些标签强加订单是不合理的。
•即使输出标签存在严格的顺序,这种真正的标签顺序在实践中通常是未知的。

将不显示完美标签顺序的这些标签视为无序集而不是或依赖序列更为合适。无序集的一个重要属性是交换不变性,这意味着交换集合中的任何两个元素都没有区别。这与laq订单的Seq2Seq模型的严格要求相冲突。因此,将使用MLE方法训练的传统Seq2Seq模型直接应用于MLTC任务是不合适的。否则,可能导致的一个实际问题是错误的惩罚。错误的惩罚意味着当生成不显示完美标签顺序的标签时,由于标签顺序不一致,MLE方法可能会错误地惩罚模型。例如,当真实标签是{a,b,c}时,即使所有标签都已正确预测,Seq2Seq模型仍会因生成标签序列[C,A,B]而受到很大的惩罚。
尽管在实践中通常无法获得完美的标签顺序,但有时人类对标签顺序的先验知识可以为标签预测提供有价值的信息以改善模型性能。例如,当la bels在有向无环图(DAG)中组织时,Nam等人。 (2017)利用标签hiernchiesto将图中具有相同祖先的标签放在彼此相邻的位置,以提高Seq2Seq模型的性能。然而,即使我们能够掌握la bel order的先验知识,Seq2Seq模型仍然可能受到影响
ñ
存在。因此,MLTC任务的适当模型应该合理地利用人类先验知识
基于这一动机,我们提出了一种新的序列到集合模型,它不仅可以合理地整合人类先验知识,还可以减少对标签顺序的依赖。所提出的模型的核心组件是leu编码器和集合解码器。由MLE方法训练的序列解码器用于融合人类先前的知识
标签订单上的模型的dence。对于集合解码器,我们应用策略梯度方法直接优化独立于标签顺序的特定度量。由于该特定度量满足集合的交换不变性,因此可以减少模型对标签顺序的依赖性。据我们所知,这项工作是第一次将强化学习算法应用于MLTC任务。
本文的贡献如下:
•我们系统地分析了多标签文本分类任务的当前模型的缺点。
•我们提出了一种基于深度强化学习的新型序列到集合模型,它不仅可以捕获标签之间的关系,还可以减少对标签顺序的依赖。
•广泛的实验结果表明,我们提出的方法大大超过了基线。进一步分析证明了提出的方法在解决错误处罚方面的有效性。
相关工作
多标签文本分类
多标签文本分类(METC)旨在为数据集中的每个样本分配多个标签。早期的MLTC任务研究工作主要集中在机器学习算法上,主要包括问题转换方法和算法适应方法。问题转换方法,如BR(Boutell等人2004),LP(Tsoumakas和Katakis 2006)和CC(Read等人2011),将MLTC任务映射到多个单标签学习任务。 Al gorithm自适应方法扩展了特定的学习算法,直接处理多标签数据。相应的代表性工作是ML-DT(Clare和King 2001),Rank-SVM(Elisseeff和Weston 2002),ML-KNN(Zhang和周2007),等等。此外,其他一些方法,如集合方法(Tsoumakas,Katakis和Vlahavas 2011),联合训练方法(Li et al.2015)等也用于MLTC任务。然而,它们只能用于捕获一阶或二阶标签相关性,或者在考虑高阶标签相关性时在计算上难以处理。
近年来,一些神经网络模型也已成功用于MLTC任务。例如,Zhang和Zhou(2006)提出的BP-MLL应用完全连接网络和成对排序损失来执行分类。 Nam等人。 (2013)进一步用交叉熵损失函数替换成对排名损失。 Kurata,Xiang和Zhou(2016)提出了一种初始化方法,通过利用神经元来模拟标签相关性。陈等人。 (2017)提出了CNN和RNN的集合方法,以捕获全局和局部语义信息。两个里程碑是Nam等人。 (2017)和杨等人。 (2018),两者都利用Seq2Seq模型来捕获标签相关性。前者探讨了不同标签排列对模型性能的影响,后者将全局嵌入增加到了等效暴露偏差。在我们的工作中,Lin等人。 (2018)提出了用于MLTC任务的基于语义单元的扩张卷积模型和Li等人。 (2018)应用标签分布式Seq2Seq模型来学习语义知识,这是METC任务的特定应用。
强化学习
强化学习(RL)探索代理人应如何采取行动与环境互动,以便最大限度地提高累积奖励。这是一个长期存在的问题,我们在这里专注于它在自然语言处理中的应用。 Ranzato等。 (2015)建议使用政策梯度法进行机器翻译和Bah- danau等人的Seq2Seq模型训练。 (2017)提出了一种训练神经网络的方法,使用actor-critic方法生成序列。 Rennie等人。 (2016)设计了图像字幕任务的自我批判训练方法,以进一步减轻曝光偏差。李等人。 (2016)应用深度强化学习来模拟聊天机器人对话中的未来奖励。 SeqGAN(Yu et al.2017)通过将生成过程视为随机策略,使生成对抗网络(Good fellow et al.2014)适应文本生成的任务。最近,刘等人。 (2018)利用强化学习模型整合本地和全球决策,以解决中国零点问题
努力将强化学习算法直接应用于MLTC任务。
结论
在本文中,我们系统地分析了h的缺点
提出了一种基于深度强化学习的新型序列到集合模型,用于融合人类先验知识,减少对标签顺序的依赖。实验结果表明,该方法在很大程度上优于竞争基线。对实验结果的进一步分析表明,我们的方法不仅捕获了标签之间的相关性,而且没有严格限制标签顺序,从而产生更好的鲁棒性和通用性。
评估序列标记中手工制作特征的效用
翻译 机器海岸线
原文 Evaluating the Utility of Hand-crafted Features in Sequence Labelling
摘要
传统观点认为,手工制作的特征对于深度学习模型来说是多余的,因为他们已经从coipora自动学习了足够的文本表达。 在这项工作中,我们通过提出一种利用手工特征的新方法来测试这一主张,作为一种新颖的混合学习方法的一部分,包含一个特征自动编码器丢失组件。 我们评估了命名实体识别(NER)的任务,我们在其中表明,包括词性,单词形状和地名词典的手动功能可以证明神经CRF模型的性能。 我们获得了Co.LLL-2003英语共享任务的91.89,其中显着地执行了一系列竞争激烈的基线模型。 我们还提出了一项研究,显示了自动编码的重要性,而不仅仅是使用输入或输出功能,而且,包括自动编码器组件在内的显示将训练要求降低到60%,同时保留相同的预测 准确性。
介绍
深度神经网络已经被证明是自然语言处理的强大框架,并且已经在许多具有挑战性的任务中表现出强大的性能,从机器翻译(Cho等,2014b,a)到文本猫。 egorisation(Zhang et al。,2015; Joulin et al。,2017; Liu et al。,2018b)。这些深度模型不仅优于传统的机器学习方法,而且还具有不需要困难的特征工程的好处。例如,Lample等人。 (2016)和Ma和Hovy(2016)提出了序列标记任务的端到端模型,并实现了最先进的结果。
与深度学习的进步正交是在特征工程上花费的精力。代表性实体识别(NER)的任务是需要lexi cal和语法知识的任务,直到最近,大多数模型严重依赖于采用手工设计特征的统计顺序标记模型(Florian等人) 。,2003; Chieu和Ng,2002; Ando和Zhang,2005)。典型的特征包括POS和块标签,前缀和后缀,以及外部地名录,所有这些都代表了计算语言学领域多年积累的戚owledge。

Collobert等人的工作。 (2011)通过学习文本组成部分的内部表示(例如,单词嵌入式)开始了无特征工程建模的趋势。通过使用在大型未注释语料库上训练的密集实值向量捕获句法和语义知识,后续工作已经取得了令人瞩目的进展(Mikolov等,2013a,b; Pennington等,2014)。通过这种嵌入式和神经网络的强大代表性能力,特征工程已经在很大程度上取代了现成的预训练单词嵌入作为输入,从而使模型完全端到端,研究重点是转向神经网络架构工程。
最近,人们越来越多地认识到语言特征的效用(Li et al。,2017; Chen et al。,2017; Wu et al。,2017; Liu et al。,2018a),这些特征被整合在一起来证明模特的表现。受此启发,以NER为案例研究,我们研究深度学习模型中手工制作功能的实用性,挑战传统智慧,以反驳手工设计功能的实用性。本文特别感兴趣的是Ma和Hovy(2016)的工作,他们引入了一个强大的端到端模型,结合了具有卷积神经网络功能的双向长短期记忆(Bi-LSTM)网络( CNN)条件随机场(CRF)中的字符编码。他们的模型非常容易捕获不仅字 – 而且还有字符级特征。我们通过集成自动编码器损耗来扩展此模型,允许模型将手工制作的特征作为输入并将其重新构造为输出,并表明即使使用这种高度竞争的模型,结合语言特征仍然是有益的。也许最接近这项研究的是Ammar等人的着作。 (2014年)和张等人。 (2017),展示如何在无人监督或半监督的环境中将CRF框架为自动编码器。

通过我们提出的模型,我们在CoNLL 2003英语NER共享任务中实现了强大的性能,其Fi为91.89,显着地执行了一系列竞争基线。我们进行消融研究,以更好地了解每个手工制作的功能的影响。最后,我们进一步提供了对不同数据量训练时模型性能的深入分析,并表明所提出的模型非常有能力,只有60%的训练集。
4。结论
在本文中,我们开始研究手工制作功能的实用性。 为此,我们提出了一种混合神经结构来验证这一假设,通过结合自动编码器丢失来扩展Bi-LSTM-CNN-CRF,将人工特征作为输入,然后重建它们。 在命名实体识别的任务中,我们显示了对一组竞争基线的显着改进,验证了这些特征的价值。 最后,本工作中介绍的方法也可以轻松应用于其他任务和模型,其中手工设计的功能提供有关数据的关键见解。
基于最小WiFi感知的相邻区域被动群速度估计
翻译 机器海岸线
原文 Passive Crowd Speed Estimation in Adjacent Regions With Minimal WiFi Sensing
摘要
在本文中,我们提出了一种使用WiFi设备估算人群速度的方法,而不依赖于人们携带任何设备。我们的方法不仅能够在WiFi链路所在的区域进行速度估算,而且能够在相邻的可能无WiFi区域进行速度估算。更具体地说,我们在一个区域中使用一对WiFi链路,其RSSI测量值然后用于估计群体速度,不仅在该区域中,而且在相邻的无WiFi区域中。我们首先证明了交叉相关性和穿越两个链路的概率如何隐含地携带关于行人速度的关键信息,并建立数学模型以将它们与行人速度联系起来。然后,我们在室内和室外进行了108次实验验证我们的方法,其中多达10人在两个相邻区域中行走,每个区域具有各种速度,表明我们的框架只需一对WiFi链接即可准确估计这些速度一个地区。例如,所有实验的NMSE为0.18。我们还在博物馆式设置中评估我们的框架,并估计不同展品的受欢迎程度。我们最终在Costco的过道中进行实验,估计买家1行为的关键属性。
介绍
考虑一个由许多地区组成的区域,例如购物中心,零售商店,博物馆或火车站。人们可能在不同地区具有不同的平均速度,取决于地区的细节,在流行度,有用性或穿越的容易性等方面。例如,百货商店的一个地区比其他地区更受欢迎,导致人们放慢速度。特定展览在博物馆中可能不太受欢迎,导致人们加速。最后,由于正在进行的施工工作,人们可能会在火车站的特定部分放慢速度。因此,研究表明,特定区域的细节可以直接影响相应区域内游客的速度[1]。在本文中,我们感兴趣的是估计这种依赖于区域的速度。由于一个人在一个地区可能没有恒定的速度,在本文中,“速度esttmatieii”指的是估计每个地区人们的平均速度,其中平均值是该特定地区人的速度的空间平均值.1换句话说,人们可以在一个地区停留几次,或者改变它们的瞬时速度。然后我们有兴趣估计它们的平均速度,这取决于地区,因此可以揭示有关地区的有价值信息。图1显示两个相邻区域的感兴趣问题(封闭区域和开放区域)的两个示例场景。我们有兴趣估计这两个区域中行人的区域相关速度,仅在一个区域中有一对WiFi链接(例如,图1中的区域1)。更重要的是,我们对大范围内的这种估计感兴趣。然后,区域2中的人的移动可能不会直接影响区域1中的链路。例如,WiFi信号可能是太弱了它到达2区,产生了一个无WiFi的区域2.因此,我们有兴趣估计不仅在地区的人群速度。

1链接在哪里,但也在相邻的可能无WiFi区域。通过仅依赖于一个区域中的感测和WiFi信号可用性来估计两个区域中的速度,我们称之为本文中仅在一个区域中具有感测的速度估计。最后,我们感兴趣的是没有人群速度估计而没有依靠人们携带任何设备,我们称之为被动速度估计。
激励范例:廉价,低成本和低功耗物联网(loT)传感器的普及为学习环境带来了很好的机会,从而实现了智能环境。了解人们在特定地区的步行速度对于多种应用是有用的。例如,零售商店可以了解产品在不同通道上的受欢迎程度,如果他们知道商店不同部分的买家*速度。例如,考虑包含特定类型产品的零售商店中的过道。如果过道中的产品不吸引他们的注意力,那么进入这个过道的购物者将以正常的速度行走。另一方面,如果他们觉得有兴趣,他们可能会放慢速度,或者停下来查看这些项目。因此,通过估计过道中行人的平均速度,可以推断产品在该过道中的流行度。反过来,这些信息可以极大地帮助进行业务规划。同样,博物馆可以根据参观者的速度估算哪些展品更受欢迎。例如,考虑一个有不同展品的博物馆。访客通常会放慢速度,在展览中花更多时间,让他们更感兴趣。因此,通过估计每个展览中参观者的平均速度,可以推断出相应展览的受欢迎程度。智能城市可以根据速度进一步设计人行横道的交通信号时序[2]。此外,识别缓慢区域可以进一步帮助
2.我们强调,如果相邻区域不是无WiFi,或者区域2中的人的移动影响传输信号,则我们的方法的工作方式相同。换句话说,我们提出的方法不依赖于相邻区域中的发送信号的可用性,并且因此如果相邻区域是无WiFi的,则可以同样良好地工作。
城市规划,例如新道路和设施的分配,或购物中心的设计。如果在特定区域估计非典型减速,则公共场所(例如火车站)可以进一步检测异常行为。然后可以相应地分配资源。
1.1相关工作
在本节中,我们将讨论估算人群速度的最新技术。
基于红外线的方法:红外(IR)传感器可用于感测环境中的人类活动。例如,已经提出计算总人数[3],[4]或跟踪人体运动[5]。最近的工作已经探索了使用被动红外传感器对人体运动的速度进行分类。例如,[6]使用三个红外传感器将走在走廊中的单个人的速度分类为慢速,中速或快速。首先利用单个人以不同速度行走的训练阶段来训练分类器,然后将分类器用于对人的速度进行分类。然而,这项工作只考虑一个行人。一般而言,没有现有的基于IR的工作可以估计一群人的速度,或者只在一个地区进行传感。更重要的是,虽然IR传感器可以在零售商店的入口和出口处获得,但是它们需要在整个商店中安装以用于收集分析,而智能loT WiFi设备已经存在于大多数商店中。尽管如此,我们注意到我们在本文中提出的方法也可以用主动IR而不是WiFi来实现,以实现具有IR的人群的速度估计。
基于视觉的方法:基于视觉的方法可以潜在地用于估计安装摄像机的直接区域中的行人速度[7] – [10]。这些方法涉及使用摄像机连续记录行人正在行走的场景的视频,然后使用计算机视觉算法来估计速度。然而,虽然出于安全目的而以按需方式探测安全摄像头的消费者很好,但是当在公共场所使用摄像机来分析客户行为时会出现严重的隐私问题。例如,最近一项关于零售购物者的调查[11]显示,75%了解基于视觉的跟踪技术能力的人发现,零售商使用这种技术追踪他们的行为是侵入性的。此外,采用这种跟踪技术可能会导致对于选择不去相应商店的购物者,如[12]中所述。总之,基于视觉的跟踪和速度估计方法具有隐私侵犯的主要缺点。此外,基于视觉的方法涉及安装摄像机和利用昂贵的复杂计算机视觉算法。例如,沃尔玛在几个月后继续使用其店内基于视觉的跟踪技术,因为它过于昂贵[13]。最后,基于视觉的技术只能估计在摄像机的直接视线范围内的人的速度。
另一方面,射频(RF)信号可以减轻与基于视觉的系统相关的一些缺点。出于这个原因,人们对利用射频信号估算行人流的某些特征,例如某个地区的行人数量[14] – [16],人们的位置[17]进行了相当大的兴趣。 ,行走方向[18],行走速度[19],以及其他传感应用[20]。特别是,使用RF信号进行速度估算的工作可分为无设备无源和基于设备的有源方法,我们将在下面进行总结。
基于设备的主动RF方法:基于设备的主动方法取决于由行人携带的移动设备提供的信息,例如媒体访问控制(MAC)数据,以跟踪人员。然而,这些方法要求购物者携带无线设备或体上传感器,这限制了它们的适用性。更重要的是,如果商店要使用购物者5设备来收集商店分析,它只能收集原始的低分辨率跟踪数据,基于监控设备在商店中连接的路由器(即,此数据可能不会直接转换为不同过道的速度估算)。即便如此,严重的隐私问题限制了这种方法在公共场所的适用性。例如,Nordstrom是一家服装公司,它实施了一种基于WiFi的商店跟踪技术,用于分析客户的行为,并因购物者的隐私问题而撤回了该公司[21]。此外,最近一项关于有源WiFi跟踪技术的调查[12]显示,80%的购物者不喜欢基于他们的智能手机进行跟踪,而43%的购物者不想在采用有源WiFi跟踪技术的商店购物。
无设备无源射频方法:另一方面,无设备无线方法利用射频信号与行人的相互作用,因此不需要行人携带任何设备。通过这种方式,他们可以保护隐私。在无设备方法中,[22]根据位于圆心中的移动电话的RSSI测量值,对在半径为2米的圆中行走的单个人的速度进行分类。使用先前训练阶段,其中当单个人在具有三种不同速度的区域中行走时收集RSSI测量值。 [23]使用FM无线电接收器对单个人的速度进行分类。类似地,使用人以不同速度行走的训练阶段。然而,在这些工作中,在该区域中仅考虑一个人,并且基于广泛的先前训练来执行单个速度的分类。在现实场景中,例如在公共场所,将有几个行人同时行走。在[24]中,几个WiFi链路的RSSI测量用于跟踪最多4个人在同一区域内行走。原则上,这种方法可以扩展到速度估计。然而,关于跟踪[25]的这项工作和其他工作通常必须假设很少的人(少于5人)。此外,为了估计一群行人的地区相关速度,不需要跟踪每个人,正如我们将在本文中看到的那样。
在我们之前的工作(这项工作的会议版本[26])中,我们已经展示了如何估计单个地区中多个人的步行速度(即,当人们在整个地区以相同的速度行走时)。这是本文考虑的情景的一个特例,其中人的速度与两个地区相同。在本文中,我们在之前的工作基础上开发了一种通用方法,可以估计两个相邻区域中人群的速度,人们可以在每个区域以不同的速度行走,仅基于一个区域的WiFi感知。
1.2目标和贡献
据我们所知,在多个地区人群的速度被动估计,只有一个地区使用无处不在的低频感应装置,尚未探索过,这是拟议工作的主要动机。更具体地说,我们在本文中的目标是估计两个相邻地区的一群行人的区域相关(平均)速度,而不需要它们携带任何无线设备,并通过测量接收信号强度(RSSI)只有一个地区的一对WiFi链接。我们的方法不仅可以在链路对的区域中估计速度,而且还可以在相邻的无WiFi区域中估计速度。它进一步表明,确实可以估计无RF区域中人群的运动属性。图1显示了具有两个区域的两个样本场景,区域1和区域2,并且具有区域相关的速度,即人们以区域1中的(平均)速度v 1和区域2中的(平均)速度行走。可以看到,区域1中安装了两个链接。然后,我们有兴趣根据区域1中链路的RSSI测量结果估算这些区域相关速度,而不依赖于人们在区域2中对链路的任何影响。我们接下来总结我们的主要贡献:
•我们通过使用马尔可夫链建模和借鉴统计数据分析的理论,在数学上表征穿越链接的概率。我们的结果揭示了交叉概率对两个区域的速度的函数依赖性。它们进一步表明两个区域的不同属性,例如区域的尺寸,如何影响交叉的概率。
•我们展示了如何使用交叉概率和两个链路的互相关来估计两个区域的平均速度。据我们所知,这是第一次使用WiFi被动地估计多个地区的人群的速度。此外,这是第一次估计相邻的无WiFi区域的速度。值得注意的是,我们的方法不需要训练阶段,人们事先以不同的速度在该区域内行走。
我们共进行了108次实验,最多10人在室内和室外区域内行走,这个区域有两个区域,每个区域有不同的速度,并且表明我们的方法可以准确地估计两个行人的速度。通过使用位于一个区域中的一对WiFi链路的RSSI测量来确定相邻区域。例如,我们对所有实验的速度估计的归一化均方误差(NMSE)为0.18。此外,当人群的速度被分类为慢,正常或快速时,整体分类准确率为85%。最后,在每个要监视的区域的总大小的链路数量相当小的意义上(例如,每14米×4.5米2个链路),感测是最小的。
•我们在博物馆环境中进一步验证我们的框架,其中有两个展览,每个展览包含非常不同类型的展示。然后,我们估计受邀访客的依赖于regios的平均速度,从而推断哪个展览更受欢迎。我们最终在Costco的过道中进行了一项实验,估计了买家运动行为的关键属性,并推断出买家对该过道产品的兴趣。
我们注意到,虽然我们展示了具有2个区域的方法,但是我们的方法可以容易地扩展到M个相邻区域中的速度估计,对于任何M> 2,具有最小的感测,即,在小于M个区域中的感测。本文的其余部分组织如下。在第2节中,我们讨论了问题设置。在第3节中,我们在数学上描述了两个关键统计数据,即交叉概率和一对WiFi链路之间的互相关,并展示了它们如何携带关于两个地区行人速度的重要信息,并提出了估算这些信息的方法。相应的速度。在第4节中,我们通过几个实验彻底验证了我们的框架。

结论
在本文中,我们提出了一个框架,通过仅在一个区域中使用一对WiFi链路的RSSI测量来估计两个相邻区域中的行人的平均速度。我们的方法仅依赖于链路所在区域的WiFi信号可用性。因此,它不仅允许估计这对链路所在的直接区域中的人群的速度,而且还能够推断相邻的无WiFi区域中的人群的速度。更具体地说,我们展示了两个关键统计数据,即交叉概率和两个链路之间的互相关,如何携带关于两个区域中行人速度的关键信息,并在数学上将它们表征为速度的函数。为了验证我们的框架,我们在室内和室外场所进行了大量实验(总共108个),最多10人,每个区域有不同的速度,并表明我们的方法可以准确估计两个地区的行人速度。此外,我们在博物馆环境中测试了我们的方法,在相邻区域展示了两个不同的展览,并估算了两个展览中的平均行人速度,从而推断哪个展览更受欢迎。最后,我们在Costco中使用了我们的框架,估计了过道中买家的动作行为,并推断出位于该过道的产品的受欢迎程度。
通过Uuasi知识图加入多文档证据来回答复杂问题
翻译 机器海岸线
原文 Answering Complex Questions by Joining Multi-Document Evidence with Uuasi Knowledge Graphs
摘要
直接回答涉及多个实体和关系的问题对于基于文本的QA来说是一个挑战。只有通过加入来自多个文档的证据才能找到答案,这个问题最为明确。策划知识图表(KGs)可能会产生良好的答案,但是由于其固有的不完整性和潜在的陈旧性而受到限制。本文介绍了QUEST,这种方法可以通过计算不同文档的部分结果的相似性连接,直接从文本源直接回答复杂问题。我们的方法完全没有监督,避免了培训数据瓶颈,能够应对用户问题中快速发展的临时主题和制定方式。 QUEST构建一个带有节点和边权重的嘈杂的准KG,由动态检索的实体名称和关系短语组成。它使用类型和语义对齐来扩充此图,并通过Group Steiner Trees的算法计算最佳答案。我们在复杂问题的基准上评估QUEST,并表明辻基本上优于最先进的基线。
介绍
1.1Motivation
网络上的问答(QA)和派生的知识来源已经得到了很好的研究[12,24,40]。研究表明,许多网络搜索查询都有问题的形式[64];随着语音搜索无处不在,这一比例正在增加[29]。本文的重点是直接回答以自然语言或电报形式提出的以事实为中心的临时问题[35,51]。这种QA的早期方法,直到IBM Watson [25]赢得了Jeopardy!智力竞赛节目,主要是使用段落检索和其他技术[49,62]进入文本来源(包括维基百科文章)。在过去几年中,将问题翻译成结构化知识图(KG)(也称为知识库(KB))和数据库(DB)(包括Linked Open Data)的正式查询的范例已经变得普遍[18,59]。 。
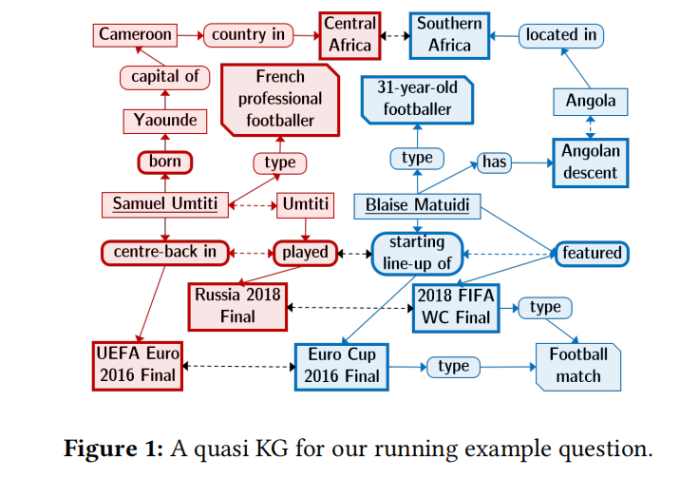
对结构化数据的质量保证将问题中的术语转换为基础KG或DB的词汇表:属性和关系的实体名称,语义类型和谓词名称。最先进的系统[1,6,7,24,69]对于涉及单个目标实体(或合格实体列表)周围的一些谓词的简单问题表现良好。然而,对于涉及多个实体和它们之间的多个关系的复杂问题,问题到查询的翻译非常具有挑战性并且成为成败点。举个例子,考虑一个问题:非洲人后裔的eefootballers参加了FIFA 2018决赛和2016年欧洲杯比赛
一个高质量的,最新的KG会得到像“Samuel Umtiti”,“Paul Pogba”或“Blaise Matuidi”这样的答案。但是,这只能将问题术语完美地映射到KG-predicates,例如bornln,playingFor对于这样复杂的问题,这种强烈的假设很少得到满足。此外,如果KG错过了一些相关的部分,例如,一支橄榄球队参加了决赛(很少赢了),那么整个查询将会失败。
1.2现有技术及其局限性
QA超过KGs。关于幼儿园QA的最新工作有几个关键的限制:(i)问题 – 查询翻译是脆弱的,往往是不可能复杂的问题,(ii)计算好的答案取决于完整性和新鲜度基础KG的内容,但没有KG涵盖所有内容并与现实世界变化的快节奏保持一致,(iii)良好查询的产生与特定语言(通常是英语)和风格(通常是完整的疑问句)相关联,并且不推广到arbiittary语言和语言寄存器,(iv)同样,翻译过程对基础KG / DB源的选择很敏感,并且不能处理仅在QA执行时看到的几个源的临时选择。
QA over text。该领域中最先进的方法面临着主要障碍:(i)要检索相关的答案提取段落,所有重要的问题术语必须在同一文档中匹配,理想情况是在短距离内。例如,如果QA系统在2018年FIFA世界杯决赛和2016年欧洲足球锦标赛决赛中发现不同新闻文章中的球员,以及维基百科的出生地信息,则没有单一文本段落可以正确回答,(ii将复杂问题分解为更简单的子问题的替代方法需要语法分解模式,这种模式分解模式可以打破不合语法的结构,也可以将子结果拼接在一起。除了问题中的时间修饰符之类的特殊情况之外,这超出了当今系统的范围。(iii)利用深度学习的现代方法临界依赖于训练数据,而这些数据对于复杂问题并不容易获得,并且对可解释性,(iv)最近关于文本 – 质量保证的工作考虑了一些问题,其中包含一个包含答案的特定文件。
本文通过提供一种新的无监督方法来克服这些局限性,该方法用于组合动态检索的多个文档的答案证据,通过从文本源自动收集的KG样式关系连接在一起。
1.3方法和贡献
我们提出了一种名为QUEST的方法和系统(用于“用Steiner树回答QUEstion”),它可以接收到swers的文本源,还集成了KG-QA(也称为KB-QA)范例的考虑因素。 QUEST首先通过动态检索与问题相关的文本文档并在其上运行开放信息提取(Open IE)[44]来构建临时的,嘈杂的知识图,以产生主题 – 谓词 – 对象(SPO)三元组。与策划的KG(如YAGO或Wikidata)相比,这些三元组包含名称和短语而不是规范化的实体和谓词,因此表现出高度的噪音。因此,我们另外计算连接潜在同义名称和短语的边缘。我们将得到的图形称为准KG,它捕获来自许多文档的组合线索,然后被视为QA算法的知识源(图1中针对足球运动员问题的例子,双向虚线表示潜在的同义词)节点)。
准KG中的节点之间的良好答案应该与所有节点(大致)匹配来自输入问题的短语很好地连接。我们将这些匹配节点称为角石(图1中具有粗边框的节点)。该标准可以投射到计算组Steiner树(GST)中,其基石为终端[26]。树的所有非终端节点都是候选答案。该计算在加权图上进行,权重基于匹配分数和提取置信度。最后,根据问题的词汇答案类型和其他标准对答案进行过滤和排序。在图1中,所有红色节点和边缘,以及所有蓝色节点和边缘,构成两个GST,分别产生答案“Samuel Umtiti”和“Blaise Matuidi”(下划线)。与大多数QA系统不同,其中正确的实体和关系链接是成功的主要瓶颈,QUEST不需要对问题概念进行任何明确的歧义消除,而是利用GST本身为模糊名称建立共同背景的效果。因此,找到GST作为相关实体的联合消歧步骤,关系和类型,因为多义概念的不同意义不太可能共享几个相互联系。值得注意的是,Steiner树提供了关于如何得出答案的可解释的见解。
特殊Web问题的本质是动态检索文档包含大量无信息和误导性内容。我们的理由是在答案计算中应对这种噪音,而不是通过在每一步中对实体消歧和关系规范化的繁琐努力,而不是试图完全清理这种输入。
GST算法已用于相关图上的关键字搜索[8,13,71],但它们适用于一类简单的关键字查询,其中唯一的节点条件是相关的。对于QA,问题要困难得多,因为输入是包含具有不同实体和谓词的多个条件的完整问题。贡献。这项工作的重点是:
•QU EST是一种新颖的方法,通过动态挖掘任意文本源并连接多个文档的子结果来计算复杂问题的直接答案。与依赖大量训练数据的神经QA方法相比,QU EST无人监督,避免了培训瓶颈和对特定基准的潜在偏差。
•QU EST是一种新颖的方法,通过动态挖掘任意文本源并连接多个文档的子结果来计算复杂问题的直接答案。 与依赖大量训练数据的神经QA方法相比,QU EST无人监督,避免了培训瓶颈和对特定基准的潜在偏差。
•QU EST结合了基于文本的QA的多功能性和KG-QA的图形结构感知,克服了仅仅KG对QA的不完整性,陈旧性和脆性的问题。
•我们设计了高级图算法,用于计算基于噪声的基于文本的实体关系图的答案。
•实验表明我们的方法的可行性及其优于最先进基线的优势。 为了便于比较和重现,可以通过以下URL公开在线演示以及此项工作的所有数据,代码和结果:http://qa.mpi-inf.mpg.de/quest/。
系统总览
复杂的问题。我们强调的是涉及多个实体和关系的复杂问题。还有其他复杂问题的概念,例如,那些需要分组,比较和聚合的问题,或者当问题涉及否定时。本文不考虑这些。回答管道。 QU EST分两个阶段处理问题:
(1)准问题的准KG的动态建设,以及
(2)用于计算排名答案的图算法。这些阶段共同包括以下五个步骤:
(la)从开放语料库(例如整个网络)中检索与问题相关的问题,
(lb)使用Open IE技术从这些文档中提取基于邻近度的SPO三元组,
(lc)从这些三元组中建立一个嘈杂的准KG,
(2a)计算准KG上的GST以得出候选答案,(2b)过滤和评分候选者以产生排名答案。
步骤(1a),文档检索,使用任何Web搜索引擎或IR系统来执行。使用合理大小的伪相关文档池可确保后续图算法在计算上易于处理。文档的预处理包括部分语音(POS)标记,命名实体识别(NER),以及通过将他,她,他,她,他和她的个人和所有格代词链接到最近的命名实体来实现轻量级共识。在前面的文字中。秒。图3和4分别给出了图形构造的步骤(1b)和(lc)以及图形算法的步骤(2a)和(2b)的细节。
7分析和讨论
图消融实验。噪声图是QUEST的支柱,有几个组件串联工作。我们通过分别停用每个组件来系统地分析这些组件的相互作用(表5)。关键的洞察力是类型节点和边缘对于QUEST的成功至关重要;删除它们会导致性能下降。接下来,使用由文档接近度和对齐级别驱动的信息性边缘权重是另一个重要元素(MRR以简并边缘权重下降)。移除对齐边缘也会对性能产生负面影响。
回答排名变体。我们的答案排名策略是通过考虑加权(具有树成本的倒数)总和以利用多个GST中的答案存在来实现的。然而,我们探索了这种选择的各种替代方案,并观察到了(表5):
(i)仅仅计算存在答案的商品及服务税是不够的;
重用节点权重来对答案评分树并没有多大帮助;
(ii)(iii)在放宽商品及服务税时考虑答案的位置,没有额外的好处;最接近基石的节点不一定是最好的答案。然而,前四个选择之间的差异不是很高:因此,只要考虑跨多个GST的答案证据,QUEST对于轻微的排名变体是稳健的。
错误分析。 QUEST的失败案例和相应的出现情况如表5所示。当QUEST无法在前5位找到任何正确答案时(Hit @ 5 = 0),我们将案例视为错误。第一种情况建议使用更好的检索模型,考虑语义匹配。第二个是失败的关键原因,并要求Open IE提取器具有更好的事实回忆。第三种情节主要是由错误的基石组合引起的。例如,在准KG中匹配关系中的’born’与clived;或’plcry’(戏剧)用作名词,匹配关系节点“播放”(角色)。这可以通过更好的NER,词典和相似性函数来改进。情况(iv)由于错误的修剪而发生。这需要更多的预测答案类型的预测和匹配,以及改进文档的类型提取。情况(v)表明,提高排名功能是提高绩效的最有价值的努力。开放IE的影响。 QUEST’S嘈杂的三重提取器导致准KG,其包含CQ-W的85.2%的正确答案(CQ-T为82.3%)。如果我们使用来自Stanford OpenlE [3]的三元组来构建准KG,那么CQ-W和CQ-T的答案分别只有46.7%和35.3%。因此,在质量保证的背景下,以精确导向,减少三倍的方式丢失信息,肯定比添加潜在的许多嘈杂的信息更痛。
回答简单的问题。在流行的WebQuestions基准测试[7]中,QUEST能够在54%的时间内找到正确的答案,与专门针对此简单问题设置的最佳QA系统相比,这是可观的。 GST使用终端的1跳邻居进行扩充,以处理双基(单实体单关系)问题。
阈值变化的影响。 QUEST中有三个参数:GST数量k,节点 – 节点相似性的对齐边缘插入阈值和节点权重的基础选择阈值。 MRR在图2中的截止等级r = 1,3.5处显示了这些参数的变化。我们观察到:(i)超出k = 50的选择值仅给出递减收益; (ii)图2b显示在图中具有多个对齐边缘(对应于非常低的阈值),实际上有助于提高性能,尽管明显引发噪声;(iii)QUEST对基石选择阈值不敏感 – 暗区,表示良好的性能,是朝着电网的内部,但广泛分布:所以大多数非极端阈值的选择将很好。右上角的白色区域对应于将两个阈值设置为非常高的值(没有选择基石,导致零性能)。
运行。 QUEST通过交互响应时间计算答案:计算GST的中位运行时间为1.5秒(平均值约为5秒)。所有实验均在Linux机器(RHEL-06.3)上使用具有256 GB RAM的Intel Xeon E5 CPU进行。
8相关工作
QA over text。经典方法[49]从与问题中的大多数提示词匹配的段落中提取答案,然后进行统计评分。 TREC在1999年至2007年期间开展了QA基准测试系列,最近重新开始作为LiveQA赛道。 IBM Wat son [25]通过将其与特殊问题类型的学习模型相结合,扩展了这种范例。
QA超过KGs。 Free-base [9],YAGO [53],DBpedia [4]和Wikidata [63]等大型知识图的出现引发了对KG的质量保证([18,59]中的概述)。目标是将自然语言问题转换为结构化查询,通常使用语义Web语言SPARQL,它直接对基础KG的实体和谓词进行操作[18,59]。关于KG-QA的早期工作建立在基于复述的映射和查询模板上,涵盖涉及单个实体谓词的简单形式的问题[7,11,23,58,67]。这条线进一步推进了[1,5,6,24,32],包括从KG中的图形模式学习模板。然而,对模板的依赖使得这些方法无法有效地应对任何句法句法。这推动了CNN和LSTM的深度学习方法[21,33,57,66,69]。这些在WebQuestions [7]和QALD [60]等基准测试中最为成功。然而,所有这些方法都以问答形式的形式建立在足够数量的训练数据上。相比之下,QUEST完全没有监督,既不需要模板也不需要训练数据。
关于混合来源的质量保证。 QA对幼稚园的限制导致考虑文本来源的复兴,与幼稚园一起[50,54,66]。 PARA LEX [23]和OQA [24]等一些方法支持在维基百科文章或网络语料库中通过Open IE [27,44]编译的三重空间形式的嘈杂KG。 Tuplelnf [39]将PARALEX扩展并推广到复杂问题,但仅限于多项选择答案选项,因此不适用于我们的任务。 TAQA [70]是基于Open-IE的QA的另一种推广,通过构建来自维基百科全文和特定问题搜索结果的n元组KG。不幸的是,这种方法仅限于介词和状语约束的问题。 [56]通过将复杂问题分解为一系列简单问题来解决复杂问题,但依赖于通过Amazon Mechanical Turk获得的培训数据。一些方法开始使用KG作为候选答案的来源,并使用像维基百科或ClueWeb这样的文本语料库作为附加证据[15,54,66],或者从文本语料库中的答案句子开始,并将这些用于实体答案的KG联合起来[50,55] ]。其中大多数都基于神经网络,并且仅针对WebQues tions,SimpleQuestions或WikiMovies基准测试中的简单问题而设计。相比之下,QU EST可以处理arbiittaty类型的复杂问题,并可以为iits答案构建解释性证据 – 这是神经方法未解决的问题。
阅读合作关系。这是一个质量保证变体,需要从给定的文本段落[34,48]回答问题。这与此处考虑的以事实为中心的答案查找任务不同,后者是来自动态检索文档的输入。尽管如此,我们还是比较了最先进的系统DrQA [12],它既可以选择相关文档,也可以从中提取答案。传统的以事实为中心的文本质量保证和多文档阅读理解最近正在成为一个被称为开放域问题回答的联合主题[16,42]。
9结论
我们提出了QUEST,这是一种基于Group Steiner Trees的动态检索文本语料库的QA无监督方法。 QUEST大大优于DrQA,这是一个在具有挑战性的基准测试中的强大深度学习基线。 由于网络内容和临时问题对于广泛的培训是不可行的,嘈杂的内容是不可避免的,QUEST故意在其计算管道中允许噪声,并使用跨文档证据,智能答案检测和基于图表的排名策略来应对。 使QUEST适应基于文本的准KG和策划幼稚园的组合将成为未来研究的重点。
序列标记:实用方法
翻译 机器海岸线
原文 Sequence Labeling: A Practical Approach
摘要
我们采用实用的方法来解决序列标记问题,假设领域专业知识的能力不足以及形成和计算资源的稀缺性。 为此,我们利用适用于各种NLP任务和语言的通用端到端Bi-LSTM神经序列标记模型。 该模型结合了从数据中提取的形态学,语义和结构线索,以得出知情预测。 modeFs性能在八个基准数据集上进行评估(包括三个任务:POS标记,NER和Chunking,以及四种语言:英语,德语,荷兰语和西班牙语)。 我们观察其中四个最先进的结果:CoNLL-2012(英语NER),CoNLL-2002(荷兰NER),GermEval 2014(德国NER),Tiger Corpus(德国POS标签),以及竞争力 其余的表现。 我们的源代码和详细的实验结果是公开的[ih“ps:// github.com / aakhundov / sequence-labeling]。
介绍
可以将各种NLP任务公式化为一般序列标记问题:给定一系列标记和一组固定标签,将一个标签分配给序列中的每个标记。我们考虑三个具体的序列标记任务:词性(POS)标记,命名实体识别(NER)和组块(也称为低分析)。 POS标记减少为为句子中的每个单词指定词性标签; NER要求检测(可能是多字的)命名实体,例如个人或组织名称; chunking旨在识别句子中的句法成分,如名词或动词短语。
传统上,使用线性统计模型处理序列标记任务,例如:隐马尔可夫模型(Kupiec,1992),最大熵马尔可夫模型(McCallum等,2000)和条件随机场(Laf ferty等。 ,2001)。在他们的开创性论文中,Col-lobert等人。 (2011)已经引入了一个深入的基于网络的解决方案来解决这个问题,这已经在这个方向上产生了巨大的研究成果。多项工作为病房后的通用序列标记引入了不同的神经结构(Huang等,2015; Lample等,2016; Ma和Hovy,2016; Chiu和Nichols,2016; Yang等,2016)。然而,为了在特定数据集上获得更好的结果,这些和其他许多工作通常采用某种形式的特征工程(Ando和Zhang,2005; Shen和Sarkar,2005; Collobert等,2011; Huang等, 2015),培训的外部数据(Ling et al。,2015; Lample et al。,2016)或以词典和地名录的形式(Ratinov和Roth,2009; Passes等,2014; Chiu和Nichols,2016)广泛的超参数搜索(Chiu和Nichols,2016; Ma和Hovy,2016),或多任务学习(Dur rett和Klein,2014; Yang等,2016)。
在本文中,我们从实际角度审视序列标记问题,采取另一种立场。上面列举的性能增强通常需要专业知识,时间或外部资源的可用性。在实际情况下,用户可能无法使用其中的一些(甚至全部)。因此,我们可以自由地避开任何形式的特征工程,预训练,外部数据(公开可用的单词嵌入除外)和耗时的超参数优化。为此,我们制定了一个单一的通用序列标记模型,并将其应用于八个不同的基准数据集,以估计我们方法的有效性。
我们的模型利用双向LSTM(Graves和Schmidhuber,2005)从句子中的单词字节中提取模态信息。这些与带有语义线索的词汇嵌入相结合,被馈送到另一个Bi-LSTM以获得词级分数。最终,单词级分数通过CRF层(Lafferty等,2001)以促进标签的结构化预定。
本文的其余部分安排如下。第2节详细说明了建议的模型。第3节和第4节描述了实验中使用的数据集和训练程序。结果在第5节中介绍。我们在第6节中查看相关工作,在第7节中总结。

6相关工作
可以说,基于深度神经网络的NLP的现代时代,特别是序列标记的现代时代,已经出现了Collobert等人的工作。 (2011年)。通过使用预先训练过的单词和特征em床上用词和单词级输入,作者已经应用了具有“最大时间”汇集和下游MLP的CNN。作为一个目标,他们最大化^句子级对数似然“,类似于2.3节中基于CRF的方法。
从那时起,提出了许多更复杂的神经模型。 Huang等人首次介绍了将Bi-LSTM网络与CRF层结合起来对句子中的单词序列进行建模。 (2015年)。作者使用了大量的工程特征以及外部地名录。凌等人。 (2015)已经提出使用字符级Bi-LSTM从单词中提取形态学信息。他们将字符级嵌入式内容与专有字嵌入(内部培训)相结合,以获得WSJ / PTB英语POS标签数据集的当前最新结果。
Santos和Guimaraes(2015)增加了Collobert等人的模型。 (2011)使用基于CNN的字符级特征提取器网络(”CharWNN”)并将结果模型应用于NER。 Chiu和Nichols(2016)将CharWNN与字级别的Bi-LSTM结合起来。 Ma和Hovy(2016)提出了类似的方法。然而,Ma和Hovy(2016)没有使用任何特征工程或外部词典,而不是Chiu和Nichols(2016),并且仍然获得了相当高的性能。
Lample等人提出的两种模型之一。 (2016)与我们的完全相似,不同之处在于作者为每种语言假设了一组固定的chtacter,而我们将字节作为编码字符级别编码的通用媒介。另外,Lample等人。 (2C16)已经预先训练了他们自己的单词嵌入,结果对他们的结果产生了至关重要的影响。
在Yang等人的着作中引入了一种将交叉语言多任务学习应用于序列标记问题的有趣方法。 (2016)。作者使用了hierarcWcal双向GRU(在字符和单词级别上)并优化了CRF目标函数的修改版本。他们的模型与应用的多任务学习框架相结合,使作者得以获得最先进的结果
7Conclusion
我们评估单个通用神经序列标记模型的性能,假设领域专业知识的不可用性以及信息和计算资源的稀缺性。该工作探讨了应用于各种NLP任务和语言的通用且资源有效的序列标签框架可以实现的前沿。
为此,我们将模型(第2节)和端到端培训方法(第4节)应用于八个基准数据集(第3节),涵盖四种语言和三项任务。获得的结果使我们确信,通过具有足够学习能力的模型,确实可以实现竞争性序列标记性能,而不必担心降低每个特定任务和语言的特定性,并召集额外的资源。
对于未来的工作,我们设想将多任务学习技术(例如,Yang等人(2016)使用的技术)整合到所提出的方法中。我们认为这可能会改善当前的结果而不会影响我们的一般应用和实用性假设。
